By Chet Brandon, CSP, CHMM
The Risk Was Already There
After a serious workplace event, organizations often move quickly to the final action. A worker reached into a pinch point. A mechanic cleared a jam under pressure. An operator opened the wrong valve. A contractor misunderstood the permit boundary. A technician accepted an exposure because the task had become routine.
Those actions matter. They need to be understood. But they are rarely the full story.
Across my career, I have seen many events where the final action was easy to identify, but the real risk was created much earlier. A worker made the last move, but the exposure had already been shaped by equipment design, planning decisions, staffing assumptions, maintenance history, production pressure, and accepted workarounds. That is why serious investigations need to follow risk upstream before settling on conclusions about behavior at the point of work.
In industrial work, risk often exists long before the final task begins. It may have been created by a design compromise, increased by deferred maintenance, reinforced by production pressure, normalized by repeated workarounds, and left unresolved by weak corrective action. By the time the worker performs the task, the risk environment may already be built around them.
The better question is not simply, “Why did the worker make the mistake?”
The better question is, “What risk environment did the worker inherit before the task ever began?”
That question is the foundation of what I call the Inherited Risk Ecosystem.
Defining the Inherited Risk Ecosystem
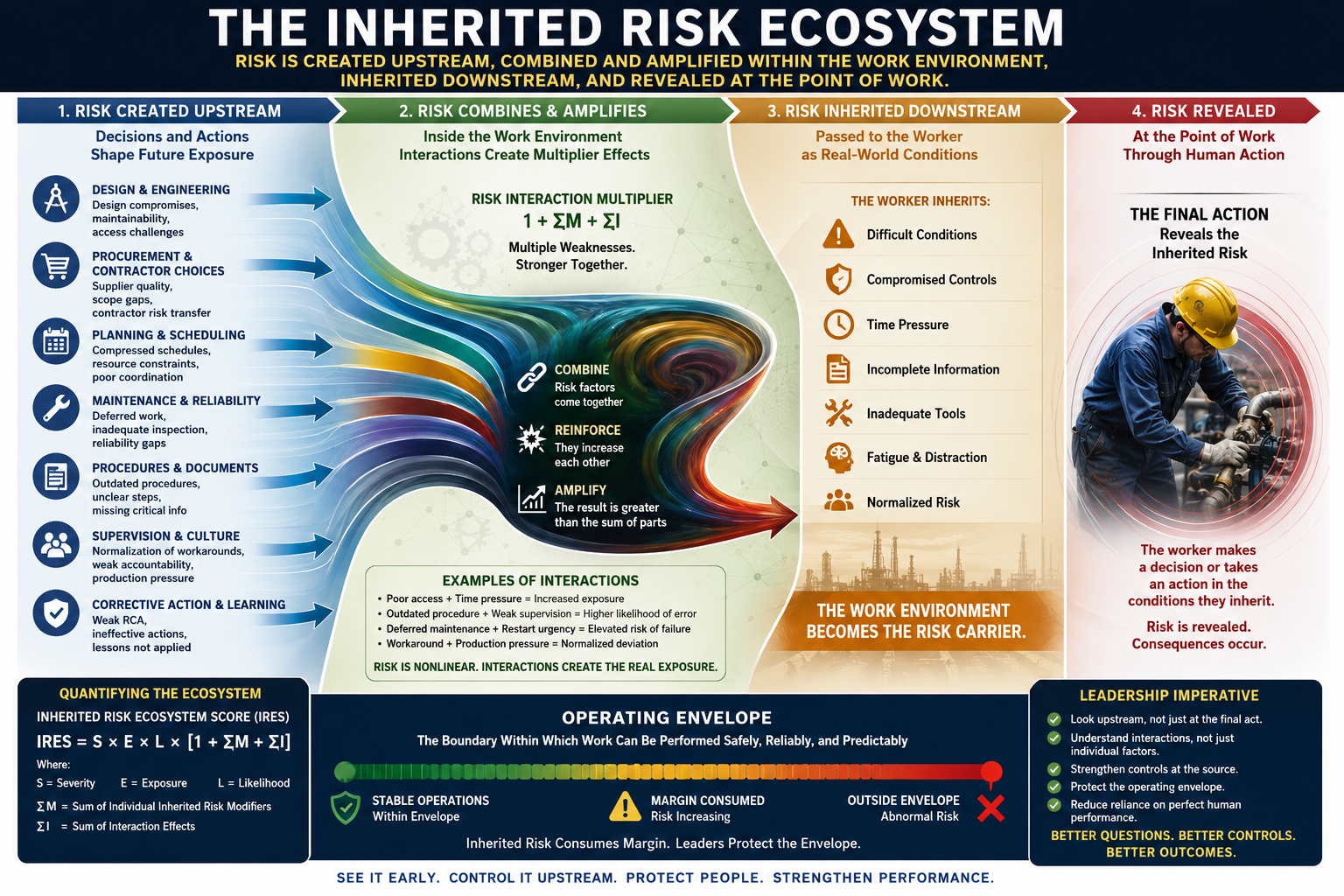
An Inherited Risk Ecosystem is created when upstream decisions, risk actions, weak controls, workarounds, and cultural norms interact in ways that shape the risk present at the point of work.
Put more simply:
Risk is created upstream, combined and amplified within the work environment, inherited downstream, and revealed at the point of work.
This concept builds on established human performance, hierarchy of controls, and Operational Integrity principles. Its specific contribution is to focus on how upstream decisions and interacting work conditions are inherited by the person performing the final task. Human error by itself has limited value as an incident cause unless the organization understands why the behavior occurred, and stronger controls reduce dependence on perfect human performance.
The word ecosystem is important. This concept is not just about a list of separate hazards. It is about the interaction of risk actions and risk conditions that accumulate inside the work environment.
A maintenance deferral may not create a serious exposure by itself. A tight production schedule may not create a serious exposure by itself. A difficult access point may not create a serious exposure by itself. A procedure that is slightly out of date may not create a serious exposure by itself. But when those conditions interact, the work environment changes. The worker is no longer managing one hazard or one imperfect condition. The worker is operating inside a combined risk environment shaped by multiple upstream choices.
That is the ecosystem.
Risk Interaction Is the Multiplier
Industrial risk is often nonlinear. One weak condition may be manageable. Two or three weak conditions interacting can create a serious exposure. The combined risk can be greater than the sum of the individual parts.
A design compromise interacts with a maintenance backlog. A maintenance backlog interacts with production pressure. Production pressure interacts with a workaround. The workaround interacts with weak supervision. Weak supervision interacts with a procedure that no longer reflects the real task. Over time, these conditions do not remain isolated. They begin to define the operating reality.
This is why leaders must look not only at individual risk factors, but at the way those factors connect, reinforce, and amplify each other. The organization may believe it is managing several small issues. In reality, those issues may be combining into one larger exposure.
This is where many serious events begin. Not with one dramatic failure, but with several ordinary weaknesses interacting in a way no one has fully recognized.
Human Error Is Shaped by the Context of Work
The concept of inherited risk connects directly to the human performance principle that error is shaped by context. People do not perform work in a vacuum. They work inside real conditions: production pressure, heat, fatigue, noise, limited access, incomplete tools, unclear procedures, poor lighting, conflicting priorities, peer norms, and leadership expectations.
The Department of Energy’s Human Performance Improvement Handbook, Volume 1 states it well: “Human error is not random; it is systematically connected to features of people’s tools, the tasks they perform, and the operating environment in which they work.” That statement aligns directly with the Inherited Risk Ecosystem concept: the final human action is often connected to the work environment created upstream.
A worker may not bypass a step simply because of poor judgment. The worker may be responding to a procedure that does not match the actual job, equipment that is difficult to access, a schedule that rewards speed, a history of tolerated shortcuts, and a supervisor who has seen the practice before without intervening.
In that moment, the human error is not isolated from the work system. It is a predictable response to the combined conditions in the ecosystem.
The goal is not to excuse error. The goal is to understand why the error made sense to the person at the time, inside the conditions they were facing. If we only label the act as a mistake, we may miss the system that made the mistake more likely. If we understand the context, we have a better chance of changing the conditions that shaped the behavior.
A Practical Way to Express Inherited Risk Quantitatively
There is value in expressing the Inherited Risk Ecosystem concept quantitatively, as long as the number is used as a leadership aid rather than false precision. The purpose is not to create a perfect mathematical model. The purpose is to make interacting risk visible.
A useful model is:
Inherited Risk Ecosystem Score = Base Task Risk × Ecosystem Interaction Multiplier
In practical terms, a higher Inherited Risk Ecosystem Score means the task is carrying more inherited risk into the field and should receive a higher level of planning, verification, and control before work proceeds.
Where:
Base Task Risk = Severity × Exposure × Likelihood
A simplified expression would be:
IRES = S × E × L × [1 + ΣM + ΣI]
In this model, S is severity potential, E is exposure frequency or duration, and L is likelihood under normal task conditions. M represents individual inherited risk modifiers, such as poor access, deferred maintenance, staffing limitations, unclear procedures, or production pressure. I represents interaction effects between risk factors, such as poor access combined with time pressure, an outdated procedure combined with weak supervision, or deferred maintenance combined with restart urgency.
The value of the model is that it forces leaders to ask whether the task is being evaluated as it appears on paper or as it actually exists in the field.
A maintenance task may have moderate base risk when viewed by itself. But if poor access, production pressure, deferred maintenance, weak supervision, and a procedure gap are all present, the risk profile changes. If those conditions also reinforce each other, the task may function as a high-risk activity even though it was not originally classified that way.
The number matters less than the discipline behind the number. The real leadership value is recognizing that ordinary risk factors can combine into extraordinary exposure.
This approach fits the EHS data-analysis method I outlined in “EHS Data Analysis Heuristics: Turning Performance Data Into Better Decisions”: start with trend review, identify the top recurring drivers through Pareto logic, compare the Best of the Best with the Worst of the Worst, look for severe exposures that may be hidden in the data, and test whether corrective actions are strong enough to control the real risk.
To make this concept easier to apply, I have also developed a practical Inherited Risk Ecosystem Score spreadsheet in excel that allows leaders, EHS professionals, supervisors, and work teams to evaluate a task using the model described above. The tool walks the user through base task risk, inherited risk modifiers, and interaction effects so the team can see whether the task is being evaluated as it appears on paper or as it actually exists in the field. The spreadsheet is not intended to replace professional judgment, pre-job planning, or required risk assessment processes. Its value is that it creates a disciplined conversation about the combined work conditions that may be increasing risk before the task begins. A downloadable copy is available here: [download link].
Trained AI models could significantly improve how organizations evaluate incidents and audit findings through the Inherited Risk Ecosystem Score framework. By rapidly reviewing narratives, observations, corrective actions, and recurring themes, AI can help identify inherited risk modifiers, interaction effects, upstream decision points, and control gaps that may be difficult to detect through manual review alone. This could enable faster screening, more consistent analysis, and earlier recognition of systemic patterns across multiple events or locations. I have created a purpose-built GPT to explore this concept and demonstrate how AI can support IRES-based analysis while keeping field verification, professional judgment, and leadership accountability at the center of the process. Explore the AI IRES tool: https://chatgpt.com/g/g-6a63ed2c0b8c819181357d09292c328c-inherited-risk-ecosystem-evaluation-tool
Understanding the Ecosystem Interaction Multiplier
The Ecosystem Interaction Multiplier is the part of the model that makes the Inherited Risk Ecosystem concept different from a traditional task risk score. Traditional risk scoring often evaluates the task as if the conditions around it are stable and independent. In real work, they rarely are.
The multiplier accounts for two things. First, it recognizes the presence of individual inherited risk modifiers, such as poor access, production pressure, deferred maintenance, unclear procedures, fatigue, contractor unfamiliarity, or weak supervision. Second, it recognizes the interaction between those modifiers. This is where the ecosystem effect occurs.
Poor access is one issue. Poor access combined with time pressure is a larger issue. Poor access, time pressure, an outdated procedure, and a normalized workaround create a different risk environment altogether. The multiplier is a practical way to show that risk factors can combine, reinforce, and amplify each other.
The value of the multiplier is not mathematical perfection. Its value is discipline. It forces the organization to ask, “Are we looking at this task by itself, or are we looking at the real work environment that surrounds the task?”
This fits the broader EHS analysis approach of looking for trends, recurring drivers, clusters, outliers, and high-impact exposures rather than reacting only to the visible event at the end of the process.
Connection to Operational Integrity and the Operating Envelope
The Inherited Risk Ecosystem concept also connects directly to Operational Integrity, particularly the idea of the operating envelope.
In many organizations, the operating envelope is understood mainly as the technical boundary of the process: pressure, temperature, flow, speed, concentration, load, or equipment capacity. Those limits matter, but they are not the whole envelope. CCPS guidance on operating procedures recognizes the importance of establishing a safe operating envelope and keeping procedures current when operating methods or related information change.
In real industrial work, the operating envelope also includes the work conditions required to keep the task safe, reliable, compliant, and under control. Procedures, permits, staffing, supervision, competency, tools, maintenance readiness, engineering controls, and field verification are all part of the practical operating envelope. CCPS also frames conduct of operations as deliberate, structured execution of operational and management tasks, tied closely to culture and the minimization of performance variation.
A process may still be within pressure and temperature limits, but the work may already be outside the safe operating envelope if the task depends on a tired crew, an accepted workaround, poor access, an outdated procedure, and a supervisor under restart pressure.
That is the practical value of the Inherited Risk Ecosystem concept. It helps leaders see that the technical process can look stable while the work system is becoming unstable.
A Simple Quantitative Example
Assume a maintenance task has a base risk score of 60, based on severity, exposure, and likelihood:
Base Task Risk = S × E × L = 5 × 4 × 3 = 60
Under normal conditions, that score may suggest a controlled but meaningful risk. However, the field conditions show several inherited risk modifiers: poor access, production pressure, a deferred repair, and an outdated procedure. Those modifiers add 0.60 to the multiplier.
The task also has interaction effects. Poor access is made worse by time pressure. The outdated procedure is made worse by weak field verification. The deferred repair is made worse by restart urgency. Those interactions add another 0.40.
The 0.40 interaction value is estimated by identifying combinations of risk factors that make each other worse. For example, poor access combined with time pressure may add 0.15, an outdated procedure combined with weak field verification may add 0.10, and deferred maintenance combined with restart urgency may add 0.15. These values are not intended to imply mathematical precision. They are a disciplined way to make risk interaction visible and to prevent leaders from treating connected weaknesses as isolated issues.
The calculation becomes:
IRES = 60 × [1 + 0.60 + 0.40]
IRES = 60 × 2.0
IRES = 120
The point is not that 120 is a perfect mathematical value. The point is that the task no longer functions like a 60. Once inherited risk modifiers and their interactions are considered, the work behaves more like a 120. That should trigger a different level of planning, verification, and control.
Inherited Risk as Operating-Envelope Stress
Inherited risk can be understood as stress on the operating envelope.
The operating envelope is not only the boundary of what the equipment or process can safely tolerate. It is also the boundary within which work can be performed safely, reliably, and predictably. That boundary depends on more than technical limits. It depends on the strength of controls, the quality of planning, the accuracy of procedures, the availability of tools, the readiness of equipment, the competency of people, and the discipline of supervision.
When upstream decisions and weak controls interact, they consume margin.
A deferred repair consumes margin. A workaround consumes margin. A procedure that no longer matches the task consumes margin. Production pressure consumes margin. Poor access consumes margin. Weak supervision consumes margin. Each condition may appear manageable on its own, but together they can push the work outside the real operating envelope.
Leaders do not need a second formula to recognize this. They need to ask a disciplined question:
Are the combined conditions of the work still within the capacity of our controls?
If the answer is no, the task has moved into abnormal risk, even if the equipment is running, the job is scheduled, and the work appears routine.
This is where Operational Integrity has to become practical. It is not enough to know that the process is within technical limits. Leaders also need to know whether the work system is still strong enough to control the risk being inherited at the point of execution.
Applying the Concept in the Workplace
The practical value of this concept is not academic. It changes how leaders review work, investigate events, design corrective actions, and manage operational risk.
In pre-job planning, leaders should ask whether the task is carrying inherited risk. Was the risk created by design? Was it increased by maintenance backlog? Was it compressed by schedule pressure? Was it transferred through contractor scope? Was it normalized through prior workarounds? Are workers being asked to compensate through attention, PPE, skill, body positioning, or judgment?
In field verification, supervisors and EHS professionals should look for combinations of weak signals, not just individual deficiencies. A missing tool is one issue. A missing tool combined with time pressure, poor access, and a known workaround is a different risk picture. That combination may indicate the task has moved outside the operating envelope.
In incident investigation, the review should not stop at the final act. A weak investigation says, “Employee failed to follow procedure.” A stronger investigation asks, “What upstream decisions made this failure more likely?” An executive-level investigation asks, “Where did our management system allow this risk to be created, transferred, normalized, or left unresolved?”
In corrective action development, corrective actions must move upstream. Retraining may be necessary, but it is rarely sufficient if the inherited risk remains in the system. Stronger corrective actions address design, access, tools, staffing, planning, scheduling, supervision, maintenance reliability, contractor management, and management of change.
In Operational Integrity governance, leaders should treat recurring workarounds, high-energy near misses, repeated procedure deviations, unresolved maintenance issues, and production-driven risk acceptance as evidence of operating-envelope stress. These are not just local problems. They may be signals that the organization is allowing inherited risk to accumulate faster than controls are being strengthened.
A Workplace Example: Line-of-Fire Exposure
Consider a line-of-fire injury during equipment clearing. The immediate finding may be, “Employee placed hand in pinch point.” That may be true, but it is incomplete.
The Inherited Risk Ecosystem view asks a different set of questions. Was the equipment designed for safe jam clearing? Was the jam condition recurring? Was jam frequency being tracked and escalated? Was the right tool available? Did production pressure influence the decision? Had supervisors seen the workaround before? Did the procedure match the real task? Was lockout practical for the frequency and nature of the issue? Had maintenance, engineering, and operations begun treating the jam as normal?
The worker’s hand in the pinch point is the final event. The inherited risk may include design weakness, poor reliability, production pressure, weak supervision, inadequate tools, and normalized deviation. Corrective action should not stop at retraining. Retraining may be necessary, but if the organization leaves the equipment condition, production pressure, procedure weakness, and workaround culture unchanged, the risk remains in the system.
A Workplace Example: Process Still Stable, Work System Unstable
Consider a process unit preparing for restart. The process parameters may be within acceptable limits. The equipment may not be in alarm. The control room may show a stable picture. From a technical standpoint, the system may appear to be inside the operating envelope.
But the work system may tell a different story. Maintenance was delayed. A valve is difficult to access. The restart window is compressed. The procedure has not been updated after a field modification. The crew is working extended hours. A supervisor is focused on production recovery. Operators have developed an informal workaround because the formal method is slow and awkward.
In this case, the equipment may still be within technical limits, but the work is drifting outside the practical operating envelope. The inherited risk ecosystem has become the real exposure.
That is exactly the type of situation leaders need to see before the event occurs.
Questions Leaders Should Ask
The leadership test is straightforward. When reviewing high-risk work or investigating an event, leaders should ask whether the work is still operating within the assumptions of the design. They should ask whether procedures match the real work, whether controls are strong enough for current conditions, whether workarounds have become normalized, whether production demands have exceeded the capacity of the control system, whether workers are being asked to compensate for upstream weakness, and whether multiple small deviations have combined into a material exposure.
Those questions move the conversation from blame to control. They also place accountability at the right level.
Workers are accountable for choices within their control. Supervisors are accountable for expectations and verification. Managers are accountable for planning, resources, staffing, and production pressure. Engineering is accountable for design and maintainability. Procurement is accountable for supplier and contractor risk. Executives are accountable for the system of priorities, governance, and risk tolerance. EHS is accountable for helping the organization see the ecosystem clearly before inherited risk becomes injury, exposure, release, or fatality.
Final Thought
The Inherited Risk Ecosystem concept gives EHS and operational leaders a more complete way to understand work. It recognizes that risk flows through the organization. It can be designed in, purchased in, scheduled in, normalized in, supervised in, or left in place by weak corrective action.
More importantly, those risks interact. They combine, reinforce, and amplify each other inside the work environment.
When I review a serious event, I am less interested in finding the first person to blame and more interested in finding the earliest point where the risk could have been recognized and controlled.
If we want better safety performance, we need to stop treating human error as the starting point of investigation. More often, human error is the point where upstream decisions and operating conditions finally become visible.
Risk is created upstream, combined and amplified within the work environment, inherited downstream, and revealed at the point of work.
The organizations that understand that will investigate better, plan better, lead better, and protect the operating envelope before normal work quietly becomes abnormal risk.
References and Further Reading
Brandon, C. — EHS Data Analysis Heuristics: Turning Performance Data Into Better Decisions. This article provides the EHS data-analysis framework referenced in this discussion, including trend review, Pareto logic, BOBs/WOWs comparison, severe-exposure review, hierarchy-of-controls thinking, corrective-action strength, prioritization, and ethical defensibility. It supports the Inherited Risk Ecosystem concept by showing how leaders can recognize patterns, recurring drivers, weak controls, and high-impact exposures before they become serious events. (leadingehs.com)
Brandon, C. — Operational Integrity: The Operating Model Heavy Manufacturing Needs. This article provides the broader Operational Integrity framework referenced in this discussion, including the operating envelope, operational discipline, operational reliability, operational resilience, and leadership cadence. It is especially relevant to the Inherited Risk Ecosystem concept because it describes how heavy manufacturing risk often fails “in layers” through bypassed procedures, degraded equipment condition, normalized workarounds, weak signals, and erosion of operational control.
CCPS / AIChE — Introduction to Conduct of Operation and Operational Discipline This source supports the Operational Integrity connection by defining conduct of operations as deliberate, structured execution of operational and management tasks tied to culture and consistency of performance. This reference also discusses operational discipline and it supports the broader operating-discipline concept that reliable execution of work is an essential part of process safety and operational excellence.
CCPS / AIChE — Introduction to Operating Procedures. This source supports the discussion of operating procedures, safe operating envelopes, and the need to keep procedures current when operating methods or related information change.
Energy Institute — Human Factors Briefing Note No. 12: Human Error and Non-Compliance. This reference supports the article’s position that “human error” alone is an incomplete incident cause and that different forms of human failure have different causes and require different remedial actions.
James Reason — Human Error: Models and Management. Reason’s work remains foundational for understanding the difference between person-focused and system-focused approaches to human error, including active failures, latent conditions, and system defenses.
NIOSH — Hierarchy of Controls. NIOSH presents the hierarchy of controls as a preferred order of actions to reduce or remove workplace hazards, with elimination, substitution, and engineering controls generally more effective because they control exposures with less reliance on human interaction.
U.S. Department of Energy — Human Performance Improvement Handbook, Volume 1: Concepts and Principles, DOE-HDBK-1028-2009. This handbook provides a useful foundation for the human-error-prevention concepts behind the Inherited Risk Ecosystem model. Volume 1 addresses human performance principles, error-likely situations, flawed controls, latent organizational weaknesses, and the role of leaders and organizations in reducing error and strengthening defenses. It supports the article’s premise that human error should not be treated as an isolated final act, but as an outcome shaped by work context, organizational conditions, and the quality of controls at the point of work.
https://www.energy.gov/ehss/articles/doe-hdbk-1028-2009